
Most UiPath projects use datatables generated from Excel files, which can be inefficient and subject to human data entry error—I have found a much more efficient solution, which I will describe here. I developed a method to retrieve data from MS SQL Server databases using stored procedures.
Using the database server and stored procedures ensures the data has integrity and consistency, as opposed to data retrieved from Excel files.
For example, those who used Excel as a data source in RPA, know the following situation: “Oops, there it should have been an integer and I had a string” (this happened because someone entered data incorrectly in a cell in Excel). The table fields in the MS SQL Server database do not allow the entry of arbitrary or null data, but only the data type in the field definition. This way, the situation mentioned above is eliminated.
Stored procedures use the database server’s processing power and immediately return the processed, filtered, and sorted data as we wish. These operations no longer need to be performed in the robot’s code using Linq. Also, the use of other additional performance-penalizing techniques (i.e. well-known For Each Row instruction) is no longer required. This ensures the reduction of execution time and processing resources.
In situations where I had access to UiPath Orchestrator, for the construction of the database connection string, I stored in the assets the necessary data (String Assets: for data source, initial catalog, app name; Integer Assets: connection timeout, server port; Credential Assets: for username and password). This technique also allowed for the used data in constructing the connection string to be re-used in more projects through linked assets. Organizations often use the same database server for multiple processes, but different databases and credentials.

I used the data taken from the MS SQL server database to populate the client application with data and dynamically generate the selectors. The dynamic generation of the selectors from the database has the following advantages: if changes of the selectors appear after the development of the project, an intervention in the robot code is no longer needed, but only the updating of the records in the database. Also, in case of subsequent processes with an identical structure, they can be managed only by modifying or adding records from the database.
For example, in one of the projects I developed, I used the MS SQL Server database to replace the config file specific to REFramework developments. We obtained a central source for taking over and managing UiPath process configurations, and could even use configuration types in different cases (dev, staging, production). We have thus eliminated the need to synchronize and adapt config files between dev, staging, and production machines. We also obtained the elimination of redundant configurations (for example, a single entry in the database is required for the name of the mail server, generally the same for all processes developed in an organization). By storing the configuration in the database, we were able to implement the use of JSON configurations and assets returned by SQL Server. The JSON can be deserialized in the UiPath process code or in MS SQL Server and after that delivered to the UiPath process as a datatable.
Another great advantage of using MS SQL Server procedures is that, in case of a well-built model, the changes can be made exclusively in stored procedures. It is not necessary to modify the robot code, thus ensuring a modularity of the whole process and eliminating the need to change RPA code, depending on the data. For example, if the records in the database are sent in a queue from UiPath Orchestrator or even directly to the client application, and it is necessary to change the order in which they are transmitted or to filter them, the only change required is the code of the stored procedure (here the reordering of the records will be ensured, according to another criterion or the elimination of some of them by a “where”- type clause ). The database server can work with data sets from different tables that it can efficiently combine through join logical operations and ensure data integrity through relationship, indexes, and constraint mechanisms. These mechanisms cannot be implemented when working with heterogeneous data sources.
Even when I had to process data from heterogeneous data sources (for example, one source from an Excel file, another source from a CSV file), another ODBC source (for example Oracle DB Server), I preferred to centralize this data through ETL techniques (Extract, Transform, Load) in an MS SQL Server database where I could combine, validate, and process the data, as well as implement a data model and its rules.
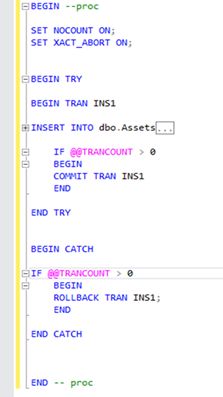
The UiPath activities used for this purpose are those in the UiPath.Database.Activities package (Execute Query, Execute Non Query, Start Transaction). The transactional mechanism for Execute Non Query activities (update, delete, insert) was ensured by the code from the stored procedures.
The database server offers:
- Consistency and integrity of processed data
- Time reduction in data collection
- Processing by using the stored procedures that are performed on the database server, to reduce pressure on the robot machine
- Retrieval of input data directly into data tables which are ready for use in the robotic process
- Dynamic generation of selectors from the database
- Join and filter operations were done in the database, which led to elimination of the need to use the Linq code in the robot code or other operations necessary for this purpose
- Possibility of centralized storage of configurations for REFramework and definition of JSON type configurations
- Decoupling the data model from the robot code
- Activities in the UiPath.Database—activities package use ADO.NET technology which communicates excellently with MS SQL Server (open source on GitHub)
- Use of MS SQL Server brought speed, accuracy and the possibility to implement data models